Hydra 2.0 Genome Project Portal
Please be aware that the Hydra 2.0 Genome Project Portal is no longer actively maintained. For up-to-date genome assemblies, please visit:
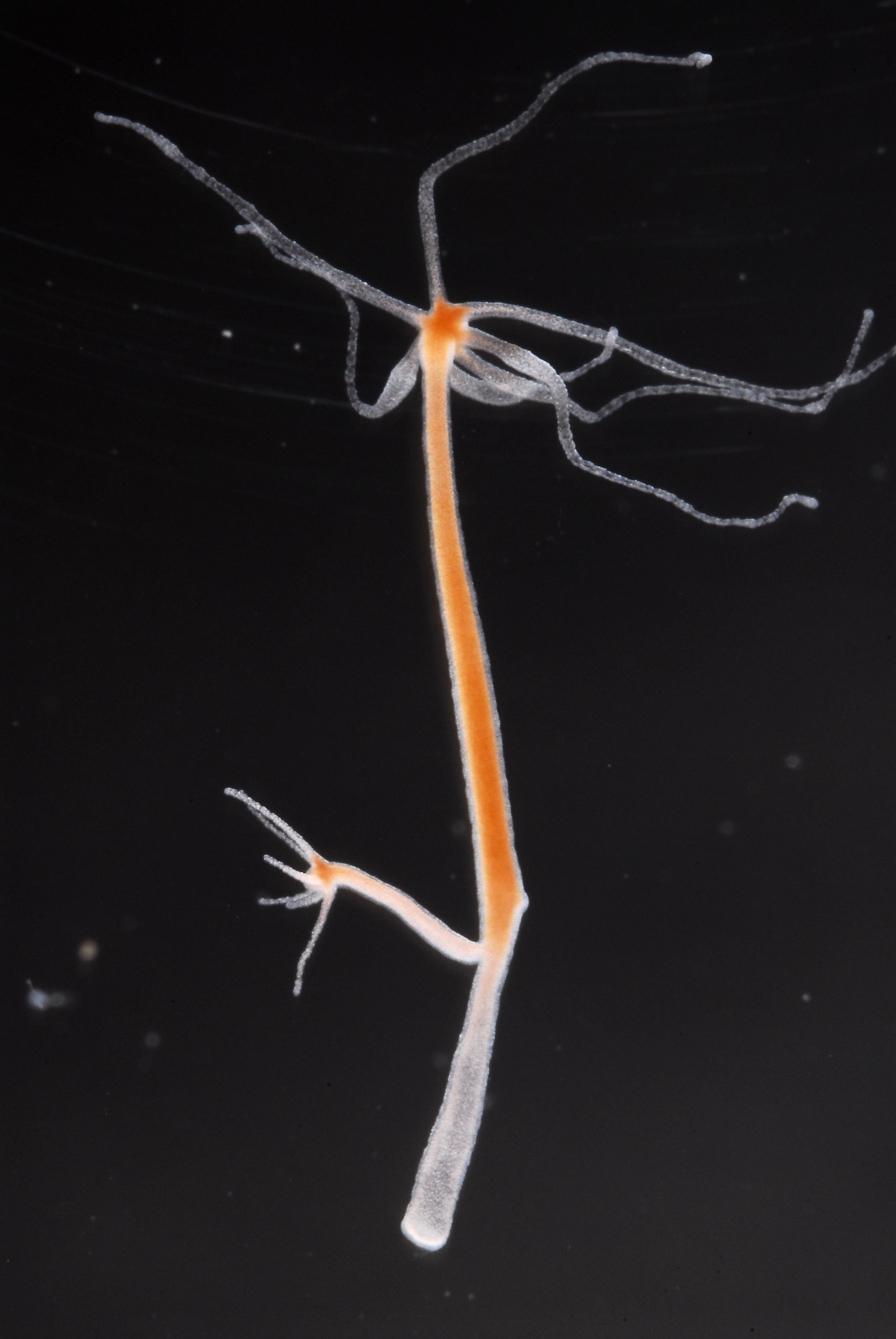
Hydra, a hydrozoan cnidarian that takes its name from the eponymous creature in Greek mythology due to its remarkable capacity for regeneration, can be thought of as one of the very first ‘model organisms’, with its unique properties first described and studied by Anton van Leeuwenhoek and Abraham Tremblay in the early 1700s.
Hydra has a morphologically simple body plan – a thin tubular and radially symmetrical body whose body wall is comprised of two layers of cells (the endoderm and ectoderm). The free end of the organism is characterized by a ring of tentacles that contain cnidocytes, the specialized stinging cells used to paralyze capture prey that are a common characteristic of all cnidarian species. Hydra possesses a basal disk at the opposite end of its body, with the basal disk secreting an adhesive fluid that allows it to secure itself to surfaces. While Hydra does not possess a brain, it does possess a nerve net that confers the ability to sense and respond to environmental stimuli and, while normally sessile, Hydra are capable of locomotion by creeping, as well as through distinctive looping and somersaulting maneuvers. Hydra is also capable of morphallaxis, a remarkable regenerative process where, after sustaining an injury, the organism is able to essentially reorganize its body, producing a smaller yet complete version of itself.
Hydra continues to be a very valuable experimental model for the study of numerous biological processes, including regeneration, senescence, axial patterning, cell signaling, and development. These types of studies have been greatly facilitated by the original sequencing of the genome of Hydra vulgaris (formerly Hydra magnipapillata) in 2010 and its re-sequencing using novel long-range sequencing approaches in 2015. The Hydra Genome Project Portal is intended to facilitate access to and use of the immense amount of large-scale sequencing data generated by both of these sequencing efforts, as well as independent transcriptomic efforts, through an intuitive and easy-to-use interface. The scope of data available through this portal goes well-beyond the sequence data available through GenBank, providing additional biological information intended to increase the utility of these sequencing data. A customized, interactive genome browser is also provided to facilitate data visualization and biological discovery. It is hoped that the availability of these data will allow investigators to advance their own research projects aimed at understanding fundamental processes of relevance to human health.
Hydra vulgaris image credit: Hiroshi Shimizu, KAUST.